Basics for Beginners — Neural Networks — Part 2
The description of how a neural network works. The following blog consists of explanation from single neuron to generalised architectures.

Neural Network
So what’s the difference between machine learning and neural network.
The neural network is the pioneering technology within machine learning, which tries to inherits the behaviour of pattern recognition abilities of human brain by processing thousands or even millions of data points. Inside the eld of machine learning, neural networks are the subset of algorithms built around a model of artificial neurons. Apart from neural network there are many more machine learning techniques that is used to forecast the outcomes.
The experiences with different situations are what makes brain learn. The brain consists of massive nerve cells that work in parallel and has capability to learn. The research has proved that in natural thinking mechanism, the brain has ability to store patterns and also to recognise individual faces. The working of brain and observation with respect to biological processing of neurons led to exploration of neural networks. This has been the motivation and ever since then it has proved its capability in various fields. The modelling of brain has promised to develop many machine solutions. Presently, this biologically inspired methods of computing has proved to be major advancement.
The neural network is composed of individual, interconnected units called neurons, nodes or units. The single artificial neuron that receives input from one or more sources can be represented as shown in Fig. The data passed to it can be binary, integers or floating point values. The node or artificial neuron takes the input and performs multiplication by a weight. Then the sum of these multiplied values are passed to an activation function. The following operation can be mathematically given as in Eq.


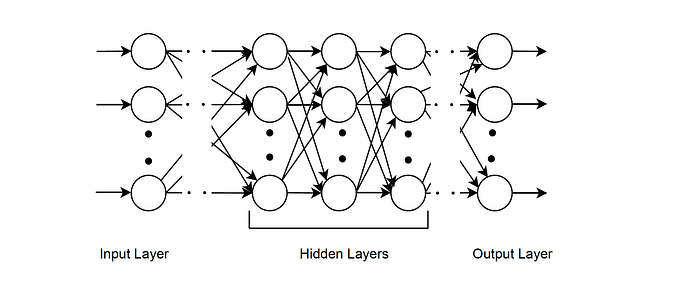
The variables x and w in the above Eq. represents the input vector and the weight vector of the neuron when there are p number of inputs to the neuron. Greek letter denotes an activation function. This process results in single output. In Fig. 2.5, the structure depicted was with just one building component. The nodes can be chained together with artificial neurons to construct a network. Neural network can have any number of layers, such as input layer, hidden layers and output layer. This type of network is called feed forward networks. The architecture is called as Multi Layer Perceptron (MLP). Fig. shows the MLP structure.
The input to the neural network can be represented as an array, in which vector is of dimension
p = dj and j denotes the layer. The dimension of the input layer decides the number of input variables. Hidden nodes helps in handling the non-linearities of the problem. They are not directly connected to the incoming data or to the eventual output. They are often grouped into fully connected hidden layers.
A trivial question regarding number of hidden nodes is usually popped out. But the answer to this will be based on the contexts. Also, the time complexity with the use of neural network is affected by number of layers. But as a rule of thumb one or two layer is suggested for feed-forward network to function virtually as a universal approximation for any mathematical function. The learn pattern are improved by adding the bias nodes to feed-forward neural networks. Bias node, function similar to input node with some constant value. This constant value depends on the context or usually its 1. The constant value here is the bias activation. The bias node helps in shifting the activation function of the output.